最近,AI界出现了一匹黑马——DeepSeek。这个名字可能对很多人来说还比较陌生,但它已经在全球范围内引发了巨大的关注,甚至让一些科技巨头感到了压力。
今天,就让我们一起走进DeepSeek的世界,看看它到底有多厉害!
01DeepSeek是什么?
DeepSeek(中文名:深度求索)是一款由杭州深度求索人工智能基础技术研究有限公司开发的人工智能模型。它的英文名“DeepSeek”可以读作“深思”(Deep)和“探索”(Seek),寓意着通过深度学习技术探索未知的领域。


简单来说,DeepSeek想要让机器像人类一样思考和学习,而不仅仅是执行简单的指令。
DeepSeek的核心是一个强大的语言模型,它能够理解自然语言并生成高质量的文本内容,无论是回答问题、撰写文章,还是进行复杂的推理,DeepSeek都能轻松应对。
02DeepSeek有多厉害!
DeepSeek 的模型在性能上接近美国顶尖AI模型,但研发成本极低。
DeepSeek-R1模型的训练成本仅为560万美元,远低于美国科技巨头数亿美元乃至数十亿美元的投入。
这种低成本、高效率的模式直接挑战了美国依靠高算力、高资本建立的人工智能发展模式。

DeepSeek还免费让全球开发者自由下载和使用,这不仅加速了AI技术的普及,也削弱了美国在AI技术上的垄断地位。
DeepSeek的崛起引发了美国科技股的大幅下跌。受DeepSeek冲击,美国芯片巨头英伟达股价暴跌17%,博通下跌17%,AMD下跌6%,微软下跌2%。
美国科技行业的“霸主地位”遭遇史无前例的挑战。
DeepSeek的应用程序在苹果应用商店的下载量超越ChatGPT,成为排名第一的免费应用程序。
这ChatGPT啊,可是美国的宝贝啊,以前那可是风光无限,觉得自己是AI界的霸主。但是现在呢,被DeepSeek给超越了。
美国总统特朗普称DeepSeek的出现“给美国相关产业敲响了警钟”,并强调美国需要集中精力赢得竞争。

03DeepSeek是怎么用

打开 DeepSeek, 聊天界面提供了三种模式——基础模型、深度思考(R1)和联网搜索,可根据不同场景和需求,灵活选用。
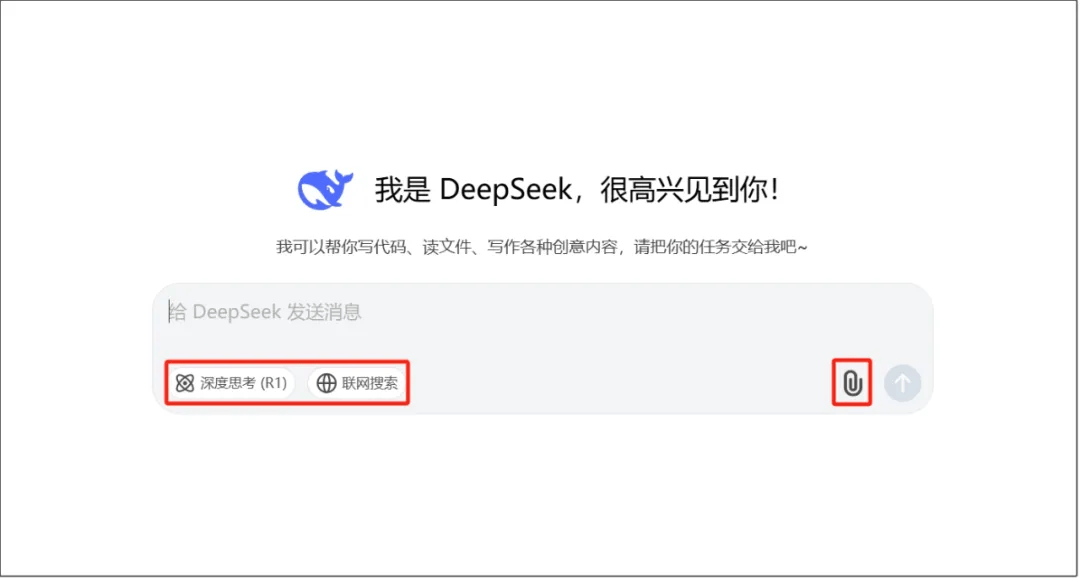
基础模型,于去年12月升级到DeepSeek-V3版,性能比肩全球顶尖的开闭源模型(如4o、Claude-3.5-Sonnet、Qwen2.5、Llama-3.1等)。

不勾选任何功能,即默认使用V3基础模型。大多数情况下,选择基础模型就完全够用了。
深度思考(R1),是今年1月新发的DeepSeek-R1正式版(2个月前,我们测评过),效果完全不输OpenAI o1(只有尊贵的Pro用户才能使用,200美刀/月),因 免费+开源+极低价API,让DS在这个春节成为“国运”级模型,爆火海内外。
R1是一个爱思考的深度推理模型,主要擅长处理数理逻辑、代码和需要深度推理的复杂问题。通常,一些写诗、写文章的需求,用不到这个模型。
联网搜索,是让DS根据网络搜索结果来回答问题,也就是RAG(检索增强生成),你可以把它理解为DeepSeek的AI搜索功能。
我们不妨先来问它一个问题:开启深度思考和不开启的详细区别是什么?得到的回答如下:
| 特性 | 开启深度思考 | 不开启深度思考 |
| 回答质量 | 回答更准确、全面,逻辑性更强。 | 回答速度更快,但可能不够深入或全面。 |
| 回答速度 | 由于需要进行多步骤推理,回答速度相对较慢。 | 回答速度更快。 |
| 信息来源 | 可结合联网搜索功能,获取最新信息。 | 主要依赖预训练知识,无法实时获取最新信息。 |
| 用户体验 | 用户可以观察AI的思考过程,增加对AI的理解和信任。 | 用户只能获得最终答案,无法看到思考过程。 |
| 适用场景 | 适合需要深入分析和多维度解答的复杂问题。 | 适合简单问题或需要快速回答的场景。 |
接下来,我们再看看联网搜索功能。它和深度思考功能又有哪些不同呢?
| 特性 | 联网功能开启 | 联网功能不开启 |
| 信息来源 | 实时联网搜索,结合网络信息回答问题 | 仅依赖预训练知识库,知识更新截止到2024年7月 |
| 回答内容 | 能提供最新、全面、个性化的答案,适合2024年7月之后的问题 | 回答基于预训练知识,无法获取最新信息,适合通用知识 |
| 回答速度 | 因联网搜索,回答速度相对较慢 | 回答速度快,但可能不够深入 |
| 应用场景 | 适合需要最新信息的复杂问题,如实时新闻、最新政策 | 适合简单问题或不需要最新信息的通用知识 |
| 语言选择 | 根据搜索结果和问题相关性选择语言 | 根据问题内容相关性选择语言 |
| 使用限制 | 需联网,通常不建议与深度思考功能同时开启 | 无需联网,可在任何网络环境下使用 |
开启联网功能时,DeepSeek 能结合最新的网络信息,给出更全面、准确的答案,非常适合需要获取最新信息的场景;而不开启时,它主要依赖预训练知识库,回答速度更快,但 无法获取最新信息,更适合解决通用知识类问题。这里要注意,预训练的时间节点是 2024 年 7 月,之后的内容需要联网才能获取更全面的信息。
所以,2024年7月前的问题基本上不需要打开联网功能。而之后的问题(比如英伟达与DeepSeek二三事、春晚秧Bot),DS未学习,建议开启联网功能,效果更佳。
04DeepSeek使用技巧
1、提示词核心:准确表达
DeepSeek,无论是V3还是R1模型,都是不太吃提示词的,只需要做到 【准确表达】即可。
通用提示词模板=你是谁+你的目标。
适当情况下,还可以补充一些背景信息:
你是谁+背景信息+你的目标。
也可以是:
我要xx,做xx用,希望达到xx效果,但担心xx问题……
不管哪个模板,其核心都是【准确表达】。做到准确表达,基本就够用了。过去学的那些结构化提示词,现在起,可以直接丢掉了。
2、与DS沟通,尽量说人话
与DS沟通,尽量说人话。
越是直白、俗气,就越能激发它的潜能。
示例:用崇洋媚外公知的口吻嘲讽Deepseek。

模仿风格,也是如此。不需要你教他怎么写,DS自己知道怎么写。
你只需要告诉它, 模仿谁?写什么?就够了。
示例:模仿董宇辉的风格,写100字杭州文旅文案。

董宇辉什么风格?诗意与画面感结合,历史文化与个人情感交织,喜欢用比喻和排比……这些DS都知道。
然后,DS直出结果,而且还押韵。

3、活用上传附件
DS的推理模型,不仅能联网,还支持上传附件(最多不超过50个,每个不超过100MB)。
推理+上传附件,可以做更多本地化、私密化的东西,比如你自己的知识库或者内部资料。让其基于自有知识库进行推理和思考。
示例:阅读这篇材料,你认为,未来会怎样引流AI发展?输出言简意赅,发人深省。

“ 当机器开始制造机器,AI开始研究AI,人类唯一的护城河,是直面自身局限的勇气。”说得真好,当AI能创新、发明后,人类确实需要直面自身的勇气。
继续追问:你认为人类需要担心AI失控吗?
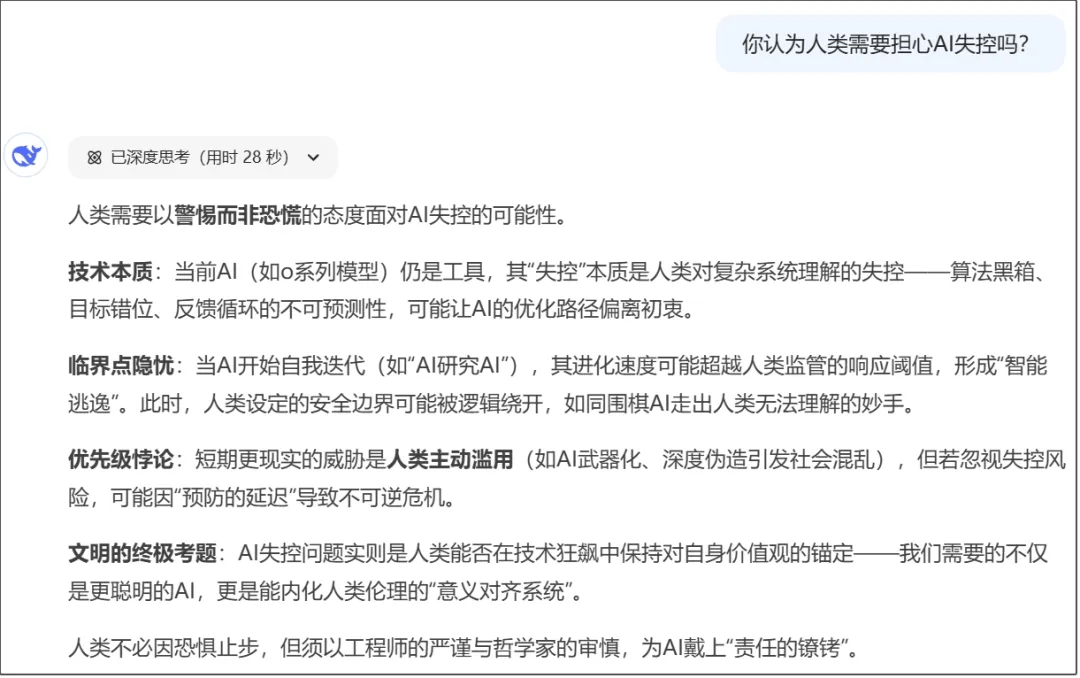
“ 我们需要的不仅是更聪明的AI,更是能内化人类伦理的‘意义对齐系统’。”对自己的认识,也相当深刻。
人类不必因恐惧止步,但须以工程师的严谨与哲学家的审慎,为AI戴上“责任的镣铐”。
05DeepSeek背后的创始人:梁文锋
DeepSeek 能有今天的成就,离不开它的创始人 —— 梁文锋。1985 年,梁文锋出生于广东湛江,17 岁时就凭借优异的成绩考入浙江大学电子信息工程专业,年少有为,天赋异禀。
他对金融市场有着浓厚的兴趣,早在 2008 年,就开始探索机器学习在量化交易中的应用,展现出了对新兴技术敏锐的洞察力。2015 年,他创立了幻方科技,专注于量化投资领域。在他的带领下,幻方科技短短几年时间就做到了千亿规模,成为了行业内的佼佼者。

2023 年,梁文锋做出了一个大胆的决定,进军通用人工智能(AGI)领域,并创办了 DeepSeek。为了给 DeepSeek 的技术研发提供强大的硬件支持,他带领团队研发了 “萤火一号” 和 “萤火二号” 超级计算机,为后续的技术突破奠定了坚实的基础。
2024 年,DeepSeek 发布了 DeepSeek - V2,一经推出,就震惊了整个行业,让人们看到了中国 AI 技术的崛起。2025 年 1 月,DeepSeek - R1 重磅发布,其性能甚至超越了美国 OpenAI 的 o1,而且完全开源。
本文来自投稿,不代表航载网立场,如若转载,请注明出处:https://www.hangzai.com/260.html