
当业界还在为千亿参数大模型的算力成本焦虑时,DeepSeek创新实现了训练效率的指数级提升。为进一步深入解析其背后的创新逻辑与实用价值,新华三集团推出《AI观析堂》专栏,将通过四期内容深入浅出的探讨DeepSeek在技术能力和经济性上的双重突破、新华三的多元化能力整合,以及这一颠覆性变革对整个行业所带来的深远影响。
DeepSeek能力强体现在哪里?
DeepSeek发布的大模型能力中,主要包括两个:
- 擅长文本生成类的,通⽤语⾔模型DeepSeek V3,「大模型中的“文科生”」
- 聚焦复杂推理和严谨思考,擅长数理逻辑、代码推理的DeepSeek R1 ,「大模型中的“理科生”」
让我们用第一个直观的例子横向评价DS-R1的逻辑思维能力:
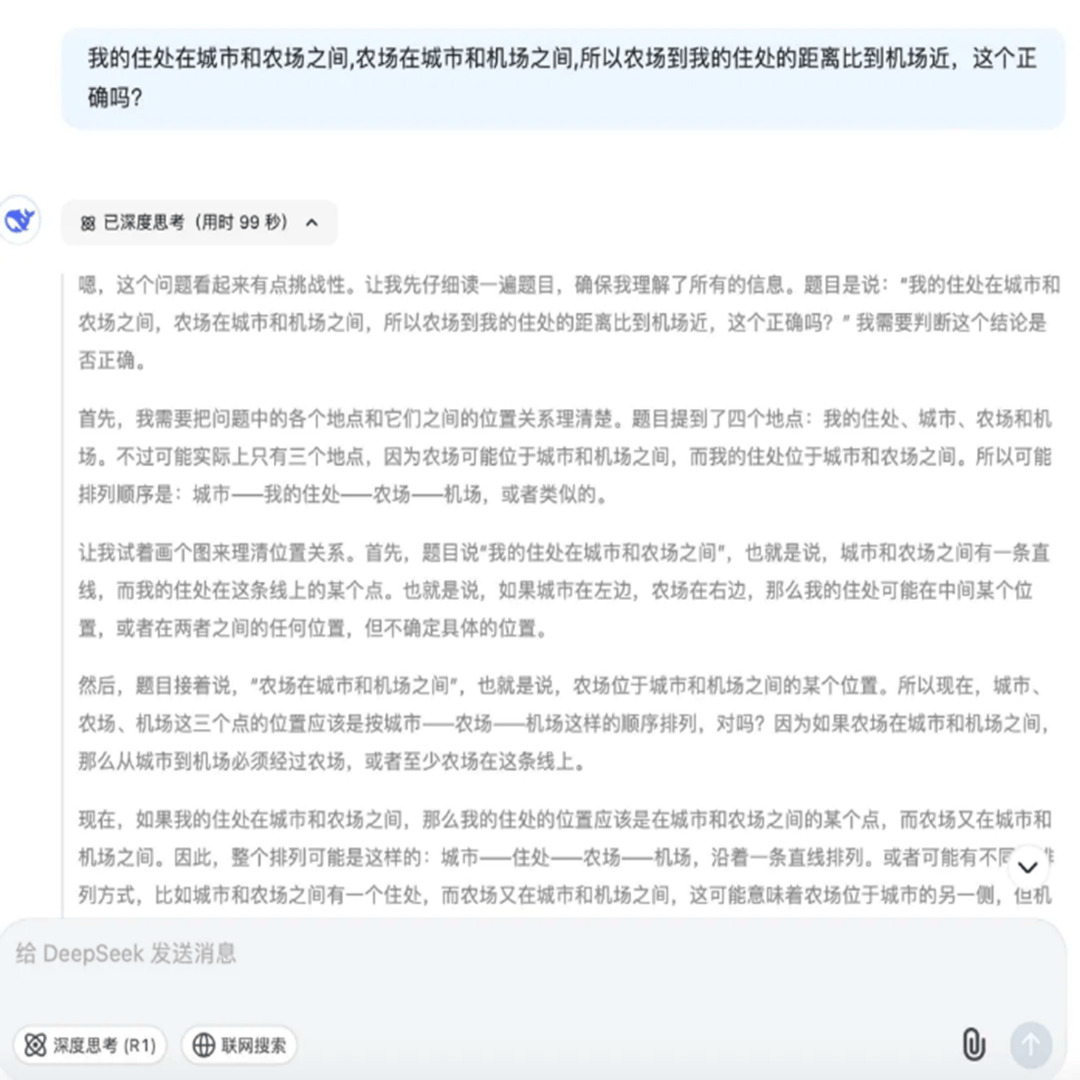
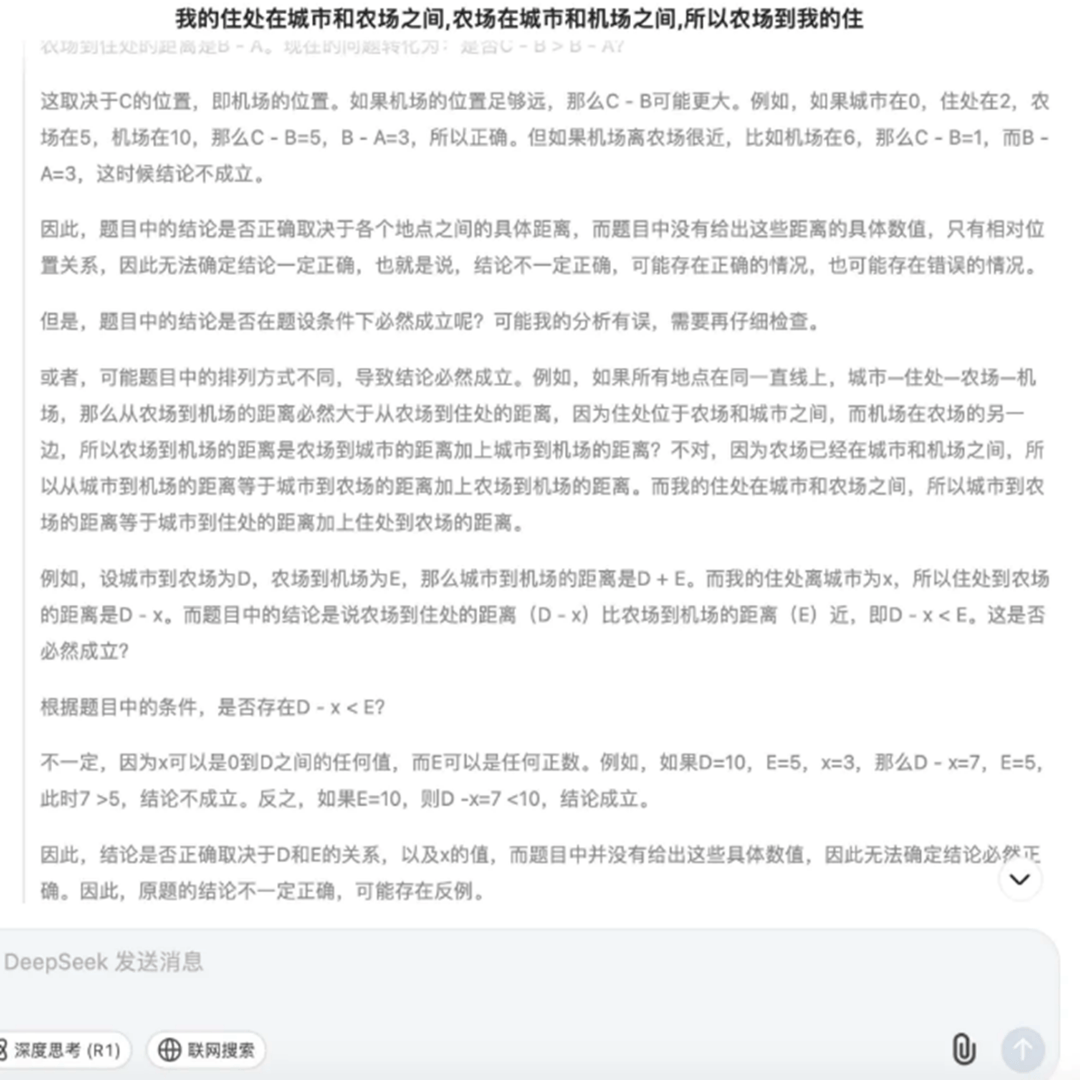
逻辑思维能力——问题: 我的住处在城市和农场之间,农场在城市和机场之间,所以农场到我的住处的距离比到机场近,这个正确吗?
DS-R1的回答(首先给出了思维链,后给了最终答案):




左右更多
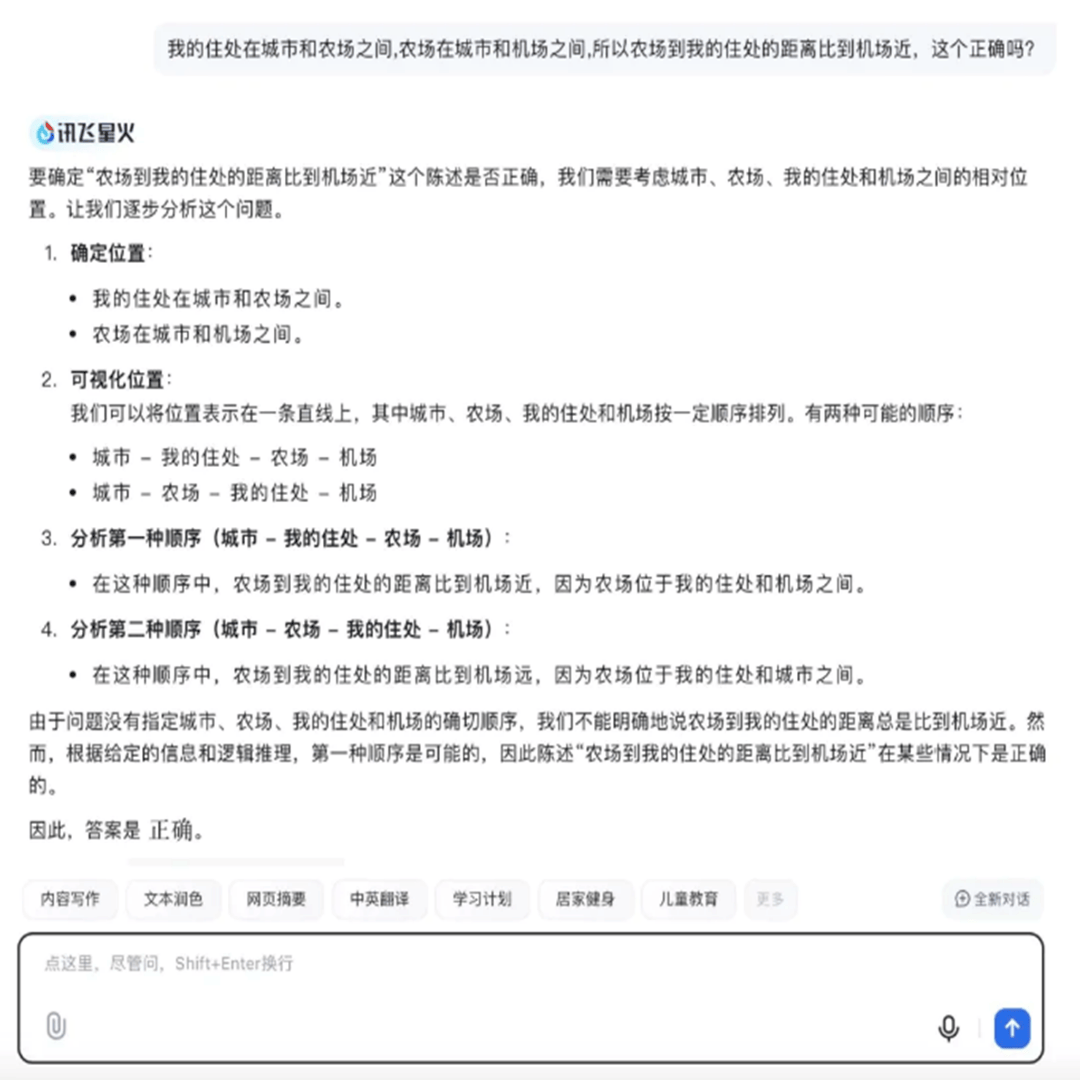
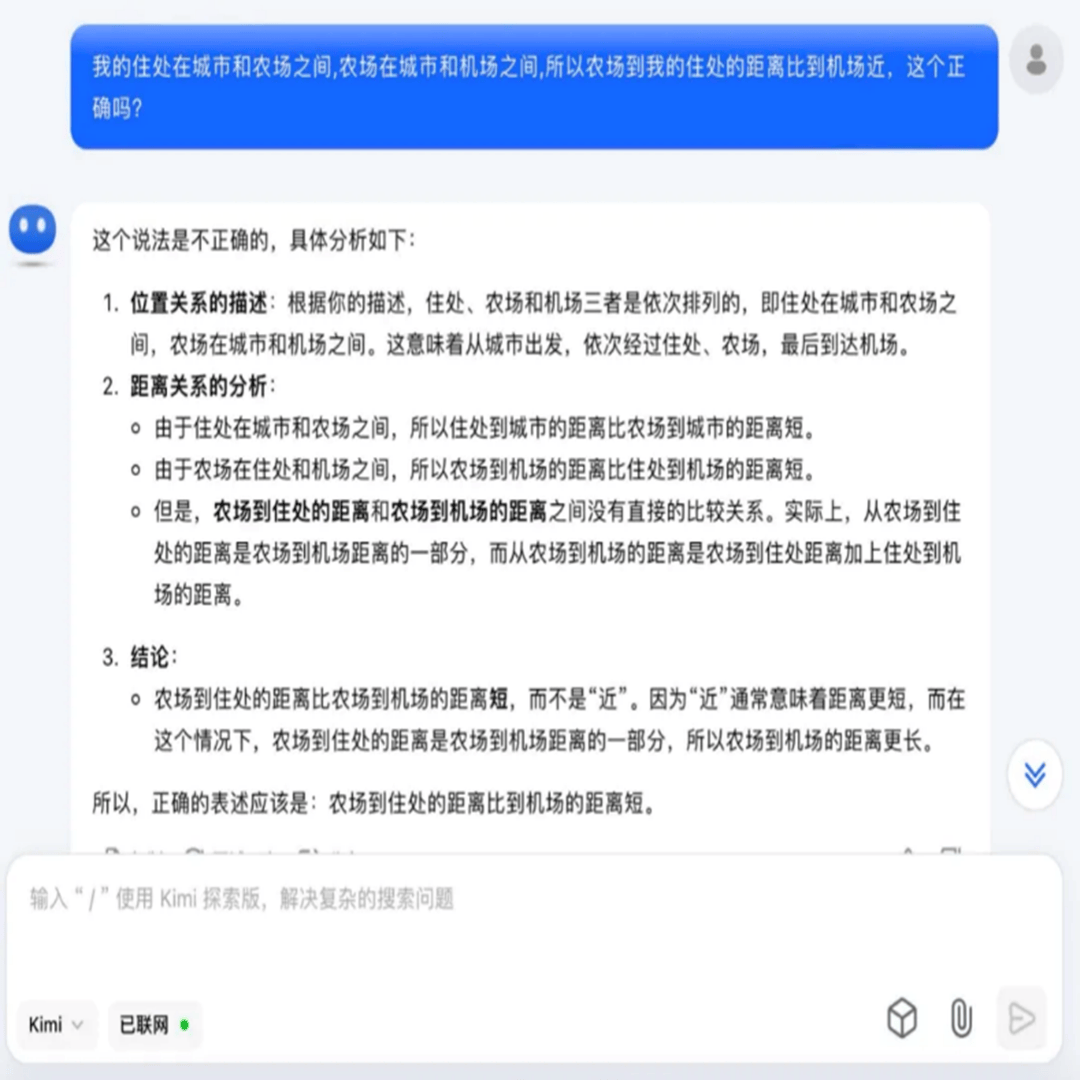
同一问题,其他模型的回答如下:
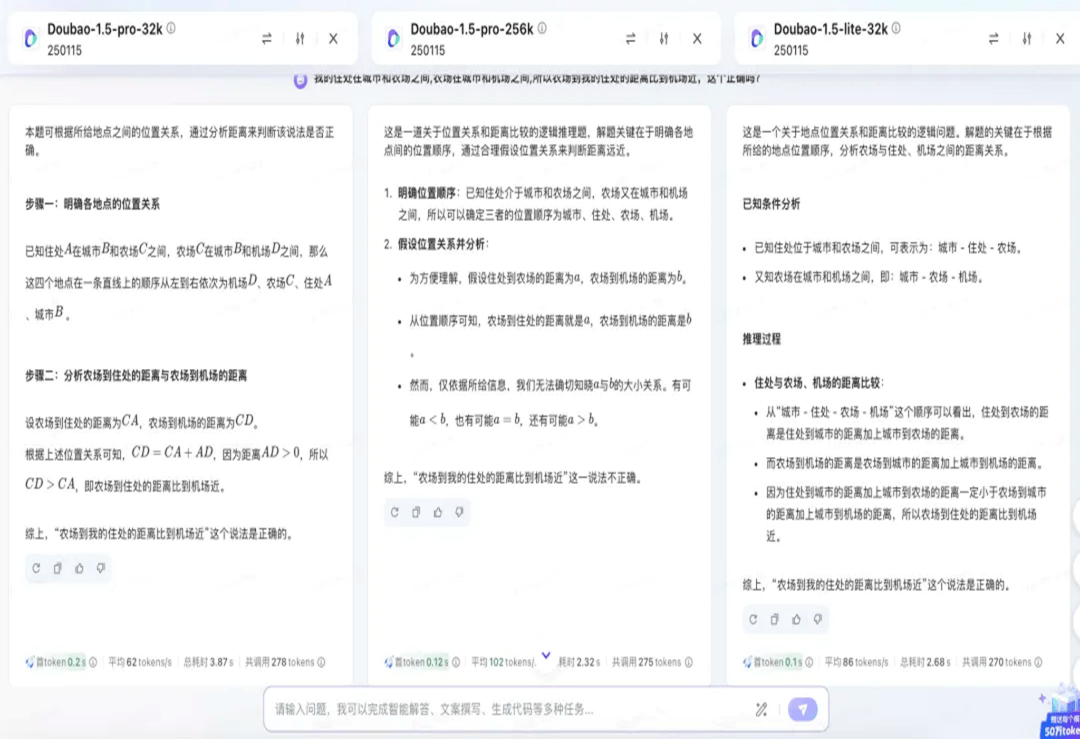
左右更多
最终贴近正确结果的是DeepSeek,其得到的结论“距离的远近取决于具体各个地点之间的实际路程长短,不能仅凭相对位置关系简单判定”。同时, DeepSeek给出了相对缜密的思维链过程,无论在形式和表现上都让人感受到智能化代来的震撼。
那么DeepSeek能力优异的技术底层关键是什么?如何通俗地理解?
要解释DeepSeek相较于其他模型的优势,起码要讲下面三点:
首先,是无辅助损失的专家(MoE)路由:
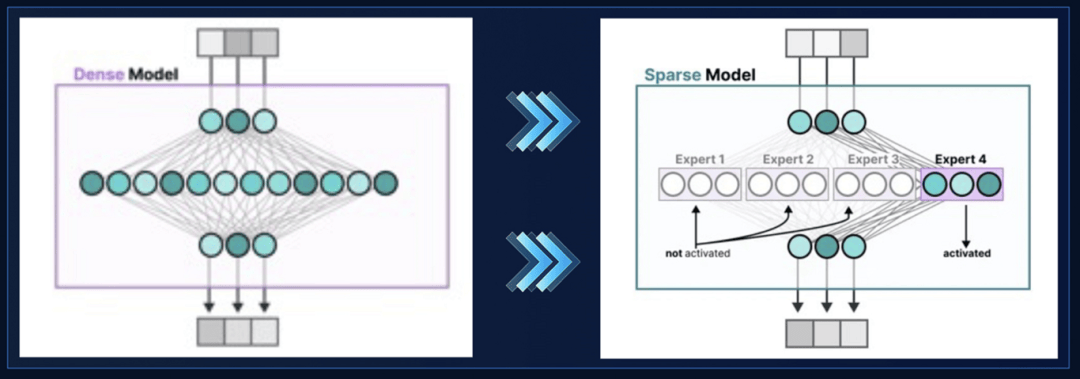
对于一个混合专家模型(MoE)架构来说
在模型计算过程当中,比起传统的所有节点“全员参与”,相当于有了一个新的分诊系统“MoE层”,就类似于医院看病的导诊台,问一个问题,不同的问题由几个不同的科室专家配合完成,病人去医院看病,不用每个科室的大夫都凑在一起,模型不用全参数投入到每一次推理任务中,大大提升了效率、降低了对硬件资源的消耗。
DeepSeek采用无辅助损失函数的负载均衡策略,舍去了路由的优化目标,模型更专注于能力上的优化目标。
相当于对分诊系统进行了优化,在计算(接待病人)的过程当中,让所有的专家“公平的”工作起来,防止偷懒,同时优化了任务分派体系,更加智能,平衡“专家科室”的压力。
此技术优化让DeepSeek更高效地处理问题。
其次,是MTP多Token预测技术:
此技术优化让DeepSeek更高效地处理问题
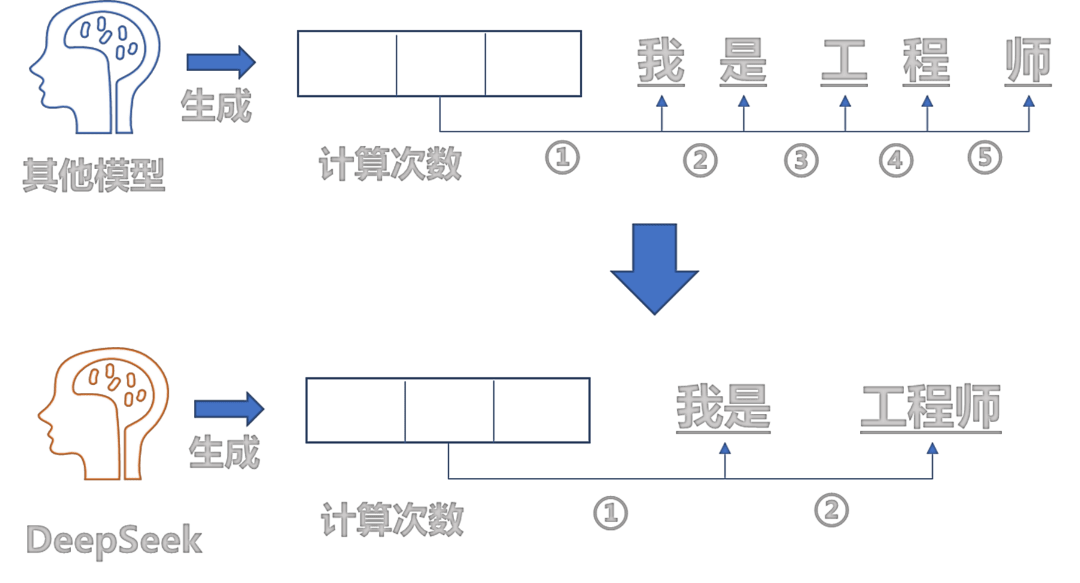
- 传统大语言模型是逐个生成Token,计算和通信量很大
- MTP是同时生成连续Token
- 优点:提升了训练时的模型智能,推理时的性能,输出更加连贯和准确
一般来说,语言模型每次只能预测一个词,但 MTP 能让模型一次性预测多个词。这就像是在下棋时提前想好好几步棋,提升了计划和决策的效率。
最后,是强化学习+监督微调训练的训练策略:
大参数模型+思维链强化学习=推理智能涌现,顿悟时刻
监督微调=让大模型用人话思考,回答更加拟人

强化学习(Reinforcement Learning,RL)是一种机器学习方法,强化学习的基础框架是马尔可夫决策过程,它允许智能体能够在与环境的交互中通过试错来学习最优策略。智能体在环境中执行行动,并根据行动的结果接收反馈,即奖励。这些奖励信号指导智能体调整其策略,以最大化长期累积奖励。
强化学习就像厨师在做完菜之后,听取顾客的评价是好吃不好吃,主动优化菜谱,客人不对具体某一步指导,但为最后的口味买单。

监督微调(Supervised Fine-Tuning,SFT)是一种在机器学习和自然语言处理领域中常用的技术,在已经预训练好的模型基础上,使用有标注的数据进行进一步训练,以调整模型的参数,使其更适应于特定的任务或领域。
监督学习类似于,学生通过大量的“例题”学习,在明确的问答中增加模型能力,对就是对,错就是错。但是这里正确的问答对很重要,也就是所谓的训练数据,这就是为什么ds只开源模型,你也不好改造他模型的原因,训练数据弄不来。
DeepSeek在R1模型训练过程中,综合多轮应用两项技术,优化了大模型推理能力和交流表现的。
DeepSeek的训练成本为什么低?
- 关于“DeepSeek训练成本低”的真相和技术解释

媒体争相报道DeepSeek训练的成本问题,引起激烈讨论
实际情况是什么样呢?国内部分自 媒体过分解读。但DeepSeek使用了大量技术提升了模型效能和H800的利用率,V3的整体训练成本的确比同级别的GTP-4o和Llama3等有大幅降低,我们解析论文估算得出:OpenAI o1 的训练成本是DeepSeek-V3的27倍!Llama 3 训练成本是DeepSeek-V3的15倍!
- DeepSeek 的训练成本较低的技术角度解读
DeepSeek 的训练成本较低,主要得益于以下几个关键技术优化:
高细粒度的混合专家(MoE)架构:
采用 DeepSeekMoE结构,在 671B 总参数中,每个 token 仅激活 37B,从而降低计算需求。
FP8 混合精度训练:
比传统的 BF16 训练更节省显存,降低存储和通信成本,同时维持模型精度。
PTX级别的指令优化:
采用 DualPipe 并行算法,减少管道并行中的计算空隙,并优化计算与通信的重叠,使跨节点专家并行训练的通信开销接近零。
高效跨节点 all-to-all 通信,使用 InfiniBand (IB) 和 NVLink 进行优化,减少 GPU 通信瓶颈。
PGRPO强化学习算法优化:
省去了 Critic 模型,减少计算开销。
太技术不好讲?没关系!四个例子教你如何通俗易懂!
高细粒度的MoE
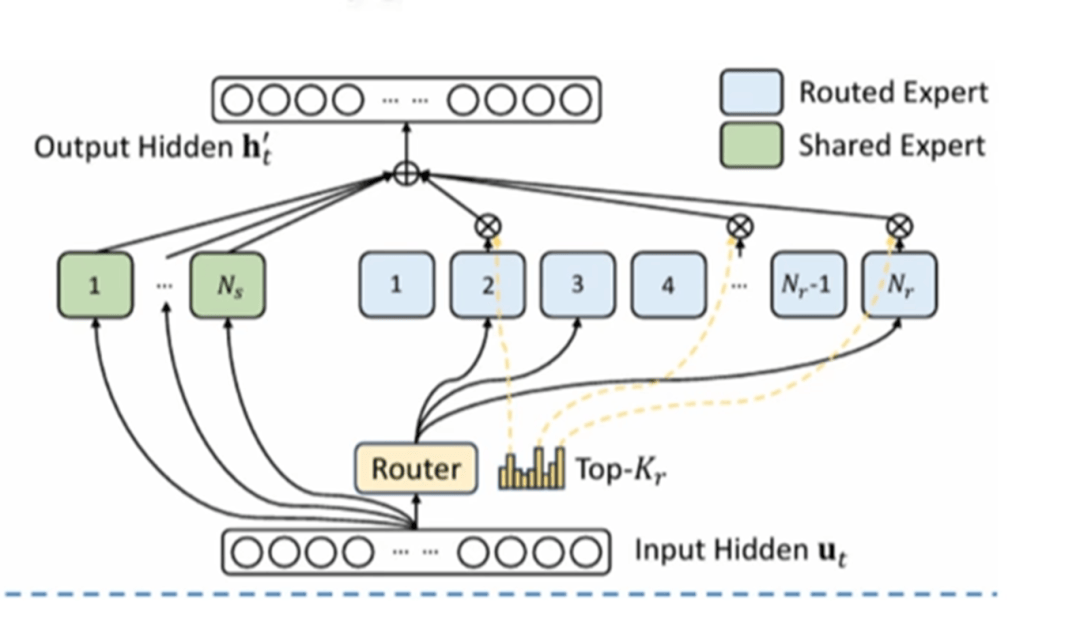

DeepSeek使用MoE架构,把大的神经网络拆成了256个“路由专家模块”,因此在训练过程中,专注训练每个“专家模块”。
就像医院每个科室的医生专注的学习自己科室的知识,不用学习所有内容,因此降低了学习成本!
FP8混合精度训练框架
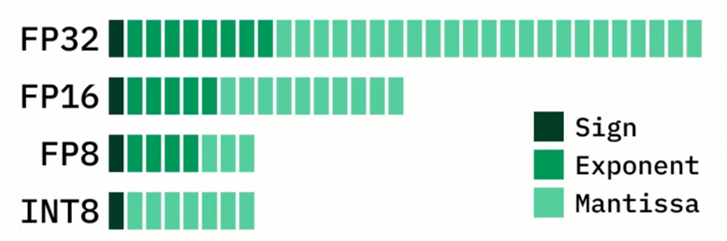
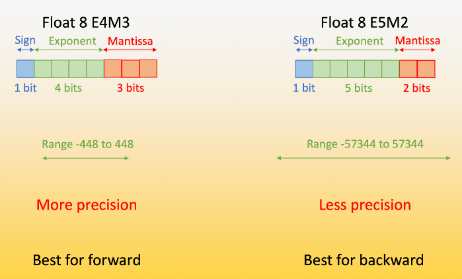
在这个框架中训练模型,大多数计算密集型操作都采用FP8精度进行,而一些关键操作则策略性地保持在它们原始的数据格式中,以平衡训练效率和数值稳定性。相比BF16/FP32减少50%显存和带宽占用。

「由青椒、土豆、少许生姜和大蒜炒制而成的青椒土豆丝」
就像我们去饭馆点菜吃饭,在菜单上、点菜过程当中、服务员下单过程中,只使用简单菜名,没有人在点菜的过程中说,你好,我想要一份「由青椒、土豆、少许生姜和大蒜炒制而成的青椒土豆丝」,这个就叫“原始数据格式”,我们说你好点一份「土豆丝」,如此便是“8位浮点数精度名称”,但是厨师在炒菜的时候,要明白这是「由青椒、土豆、少许生姜和大蒜炒制而成的青椒土豆丝」,这就是混合精度的价值。
FP8混合精度训练可以保持必要精度,节约显存占用、提高通信速度、加快计算。
PTX优化技术-跨节点通信
定义:
- Nvidia为其GPU设计的一种中间指令集架构。
- PTX位于高层次GPU编程语言(如CUDA C/C++或者其他语言前言)和低层次机器码(流式汇编或者SASS)之间。
- PTX是一种close-to-metal ISA,将GPU看作数据并行计算设备,因此允许进行细粒度优化。比如寄存器分配和线程级别的调整,这是CUDA C/C++和其他语言无法实现的。
- 当PTX进入SASS,它就会针对特定代的Nvidia GPU进行优化。
用途:
- 当训练V3模型时,DeepSeek对H800 GPU进行重新配置:在132个SM中,其分配了20个用于服务器到服务器之间的通信,可能用于压缩和解压缩数据,以克服处理器的链接限制并加快事务处理速度。
- 为了最大化性能,DeepSeek也实现了先进的管线算法,可能时进行更加精细的线程调整。
- 特点:硬件利用率高,和特定产品型号深度绑定,难以移植。

想象一个繁忙的十字路口(代表GPU的计算和通信任务):
- 普通交通管理(高层编程语言如CUDA):红绿灯按固定周期切换,所有车辆(计算/通信任务)必须排队等待。虽然规则简单,但高峰期容易拥堵,救护车(关键通信任务)可能被堵在车流中。
- 智能交通优化(PTX底层汇编):交通工程师(开发者)直接调整红绿灯时序,为救护车开辟专用车道(定制通信内核),动态分配车道资源(如IB和NVLink带宽),甚至让部分车辆借道逆行(绕过默认调度规则)。最终,救护车能无阻通行,普通车辆也能高效流动。
DualPipe流水线优化
双流水线并行策略,让计算与通信近乎重叠,大大减少了训练时GPU不干活干看着的时间。
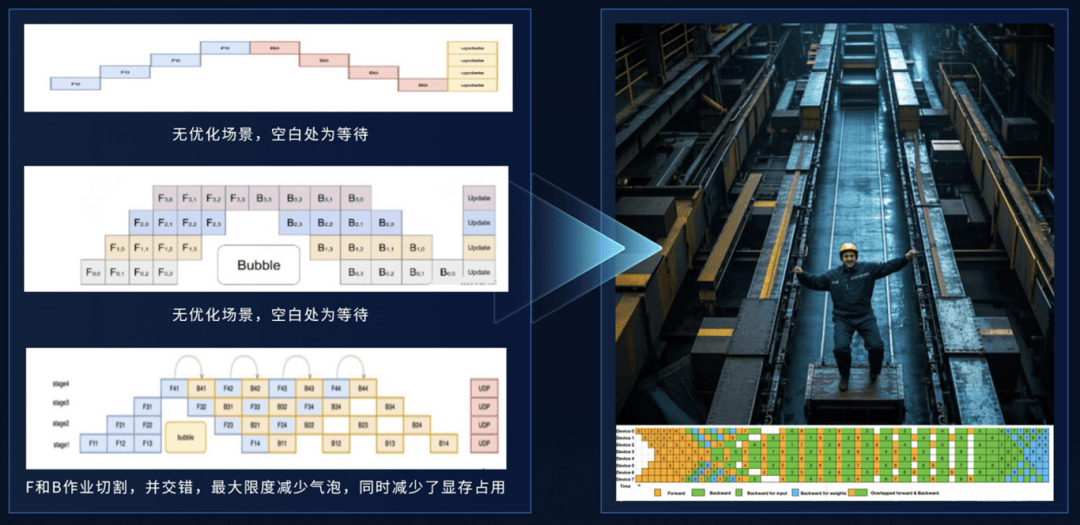
想象一名工人(GPU计算单元)在一个流水线上工作,还得等工件送过来,两个流水线在他左右,他做完左边的右边的工件刚好到,然后就做右边的,做完了左边的又到了,提高算力应用
GRPO强化学习算法
GRPO 是一种高效强化学习算法,旨在降低训练成本,同时避免传统方法对价值评估模型(Critic),的依赖。其核心思路是:通过组内输出的相对比较来估计策略更新的方向,而非依赖单独训练的评论家模型评估每个状态的价值。
GRPO算法抛弃了训练时不必要的负担:
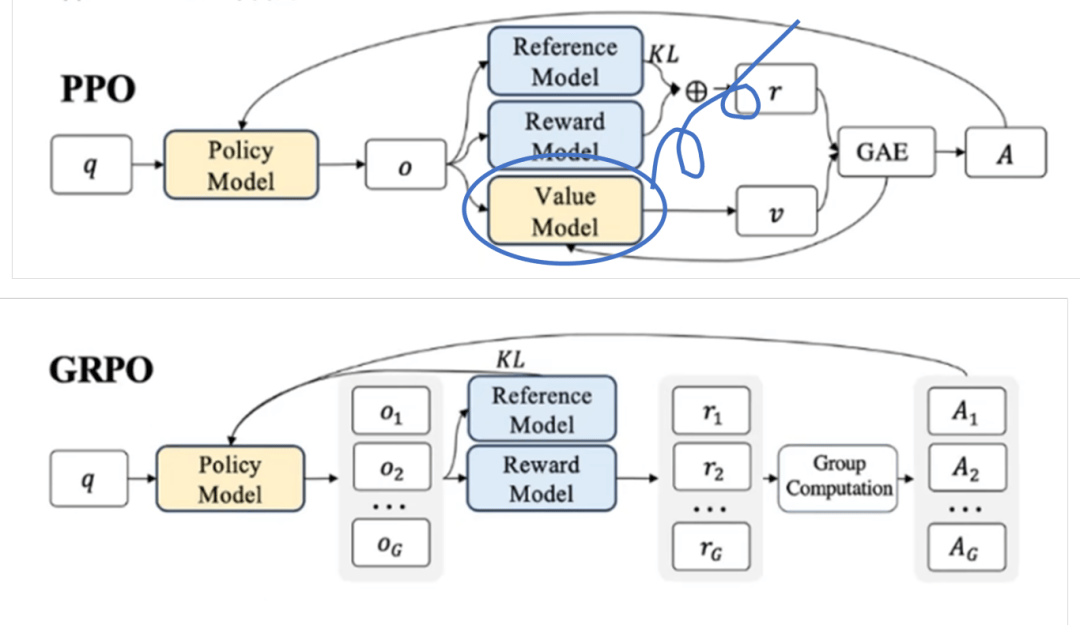
- 传统的强化学习,需要“评价模型”参与
- GRPO:舍弃“评价模型”直接利用“评分标准进行评分”


类比两种工作方式,传统的强化学习,是公司新人在“师傅”的指导和监督下开展工作的。Grpo更像是几个新人之间按照工作评价表,打分进行比较,开展工作。
精彩预告

在AI技术的落地应用中,成本和易用性是关键考量。是什么让DeepSeek的部署如此经济实惠又易于被广泛采用?下期文章我们将深入剖析这些问题,敬请期待!

《AI观析堂》全期内容概览
第一期:DeepSeek热点技术解读(1)
- DeepSeek能力强体现在哪里?
- DeepSeek的训练成本为什么低?
第二期:DeepSeek热点技术解读(2)
- DeepSeek部署成本为什么低?
- 是什么让我们更容易用上了DeepSeek
第三期:结合DeepSeek,新华三提供大量能力
- 推理部署
- 产品提供
- 智慧化服务
第四期:DeepSeek热点对行业的影响
- 整个产业都被如何影响(模型、GPU、整机、推理、云、应用
原创文章,作者:航载网,如若转载,请注明出处:https://www.hangzai.com/302.html